Q. 왜 .... **name 이야 ? 왜 이중 포인터 배열을 쓴거야 ??
1. 개요

예를 들어,

이와 같이, 명령 프롬프트 다음에 특정 명령을 입력하지 않고, 엔터를 쳐서 그 다음 줄로 넘어가게 되면,
명령 프롬프트 다음으로 넘어가는 것이 아니라,
엔터를 쳐서 그다음으로 넘어가게 된다.
따라서 우리는, 명령 프롬프트를 실행해서, 아무런 명령 없이 엔터를 쳐도, 그 다음 명령 프롬프트로 바로 넘어갈 수 있게 해주는 것이 목적이다.
또한, 이상한 명령어를 넣으면, 그에 해당하는 적절한 오류 메시지를 출력하도록 해주는 것이다.
이를 위해서는
사용자가 엔터를 칠 때까지, 그것이 몇개의 단위로 구성되었는지 관계없이, 라인 단위로 입력을 받고, 그에 대한 처리를 하는 것이 필요하다.
배열의 용량을 초과할 경우에는, 동적 메모리 할당으로 배열의 크기를 키워야 한다.
2. 자료구조
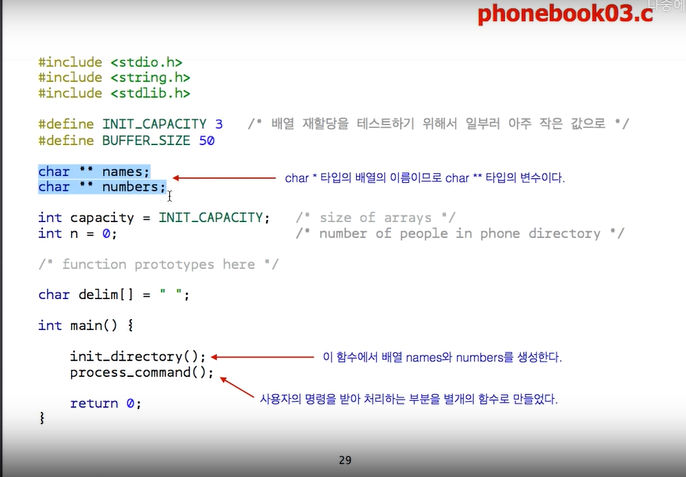
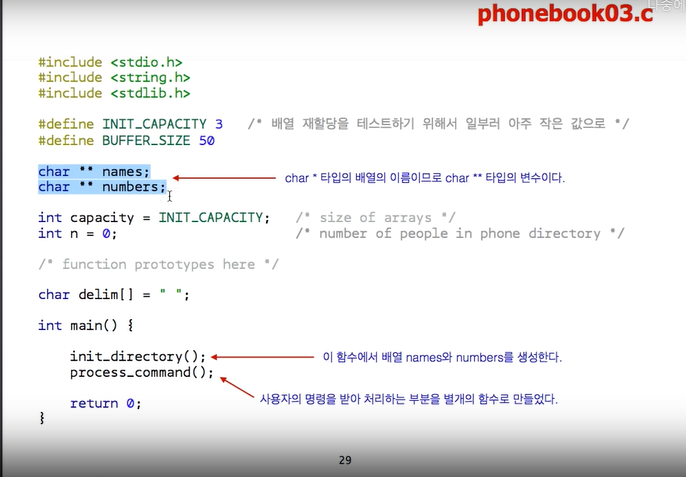
자료구조 부분에서 큰 변화.
지금까지는 우리가 사람 이름과, 전화 번호부를 저장할 부분을 배열로 설정했는데, 이 배열의 크기를 필요시 더 키우기 위해, names, numbers 를 더 배열이 아니라, 포인터로 선언한다.
배열.의 이름은, 사실 그 배열의 시작 주소를 저장하는 포인터 변수.
그래서, 이것이 어떤 의미에서는 ,names 라는 변수의 type 이 바뀌는 것은 아니다. 그 전에는, ex. char * name [ CAPACITY ].
그저 여기서는 이중 포인터 개념이 쓰이는 것이다.
사실상 같다. names 는 이미 주소값을 가지고 있는 포인터 변수이기 때문에 names[ ] 에서, *names 라고 해도 크게 이상한 것은 없다.
자 . 여기서 궁금한 것은 .... 한칸에 char *. 라는 의미는... 한칸의 크기가 char * 만큼이라는 것인데, 이것의 크기를 고정되어 있는거야 ? 왜냐하면, 이것이 가리키는 주소. 거기의 크기만큼 할당이 되는 거라면, 각 칸의 크기는 다른 거 아니야 ? 아니지. 전화번호부 2.0 까지도 *names[ 30 ]. 정적 할당한 것도, 사실 한칸은 포인터 변수이니까. 원리는 같아.
다만 지금까지는 정적 할당을 한 것이고, 이제부터는 동적 할당을 할거야. 그때그때 배열의 크기를 재조정하려고.
int capacity : 배열의 현재 size
n : 저장된 사람 수
3. init_directory

이름과, 전화번호부 배열을 동적 메모리 할당으로 지정한다.
names = (char **) malloc( INIT_CAPACITY * sizeof ( char * ) )
sizeof( char * ) : 포인터 각 칸에 char * 를 저장할 것이기 때문에 이와 같이 설정했다 .
배열의 한칸의 size가 sizeof( char * ) 가 되는 것이다.
문자열 포인터를 저장하는 것이니까.
즉, INIT_CAPCITY가 3, 현재 초기화 하는 배열의 크기, 한칸의 크기가 char *, 즉, char * 포인터 변수의 크기. .
4. process_command

3번째 버전에서 가장 중요한 것은, 사용자의 입력을 단어가 아니라, 문장 단위로 입력받는 것.
command_line [ BUFFER_SIZE] : 한 라인을 통째로 읽어오기 위한 버퍼.
즉, 엔터를 탁 치면, 그때까지 입력한 애를 모두 저장하는 것이다.
if( read_line( command_line, BUFFER_SIZE) ≤ 0 )
이를 통해, 우리가 입력해서 command_line 에 저장한 내용을 읽는 것인데, read_line 은 읽은 문자 개수를 리턴하도록 했으므로, ≤ 0 이라는 것은, 읽어진 내용이 없다는 의미. 그러므로, 이 경우에는, 사용자가 아무 명령없이 엔터친 경우에 해당한다. 따라서, while 문 처음으로 다시 돌아가도록 한다.
command = strtok( command_line , delim )
if( command == NULL) continue;
사용자가 입력한 것은 command_line 이다. 하나의 긴 string 이다.
그 긴 string 을 우리는 delim, 즉, 공백 문자를 기준으로 자르는 것이다.
만약 command, 즉, 리턴된 token 값이 0 이라면, 다시 while 초로 돌아가기.
if( strcmp( command, "read" ) == 0 )
argument1 = strtok( NULL , delim );
if ( argument 1 == NULL ) {
printf( "File name required. \n" ) ;
continue;
이제, 입력받은 애들을 우리의 함수들과 비교하는 것이다.
그리고 입력받은 command 애들을 연속해서 strtok 을 하는 과정이다.
그래서 첫번째 매개변수는 그다음부터 null 이 된다.
argument1 = strtok( NULL, delim );
얘가 return 해주는 것은 2번째 token의 주소가 될 것이다.
if( argument1 == NULL ) 이라는 것은, 사용자가 파일이름을 입력하지 않고 엔터를 친 것. 그래서 continue 로 다시 돌아가기.
즉, 다시 $ ( 프롬프트) 출력과 함께, 다시 사용자 입력하도록 설정하는 것.

load 에서, 사용자가 이름과, 번호를 입력하게 되면,
add 라는 별도의 함수를 통해 정보를 추가한다.
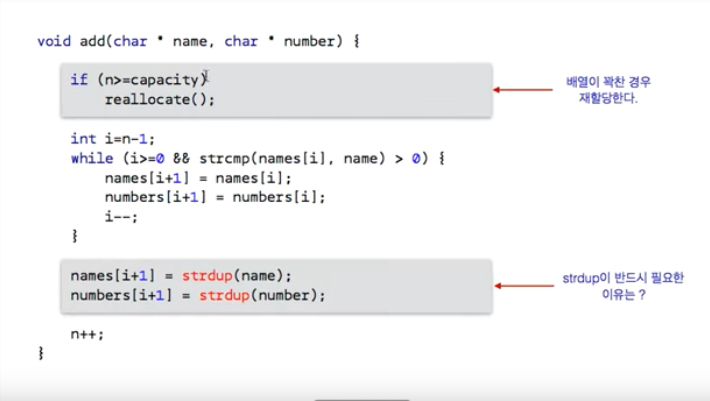
이후, strtok 관련 명령어들을 참고해보자

add 명령어 같은 경우, 사람 이름과 전화번호부가 뒤따라야 한다.
그래서 연속 2번해서 strtok 를 실시하는 것이다.
if( argument1 == NULL || argument2 == NULL )
사용자가 사람이름 혹은 전화번호부 둘 중 하나라도 입력을 안한 경우
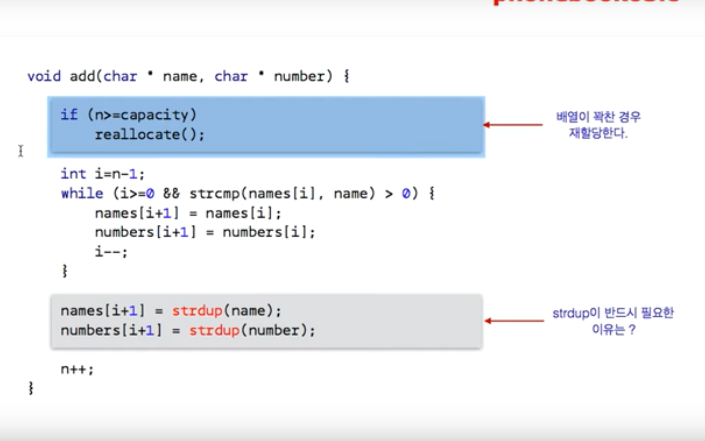
reallocate : 배열 재할당
그리고, 현재 capacity 에 INIT_CAPACITY가 할당이 되었고, 이는 names, numbers 라는 두 배열의 현재 크기를 말하는 것이다.
n 은 현재 배열에 저장된 사람 수
n == capacity 라는 것은 현재 저장된 사람의 수가 배열의 크기와 동일한 만큼 할당되었다는 것인데,
n ≥ capacity 라는 것은, 실제로 배열이 꽉 차서, 새로운 사람을 추가할 여유공간이 없다는 것이다. 이 경우, reallocate( ) 를 통해, 배열의 크기를 키워줘야 한다.


처음에 우리는 names, numbers 에, INIT_CAPACITY 만큼, 배열의 크기를 할당해주었다.

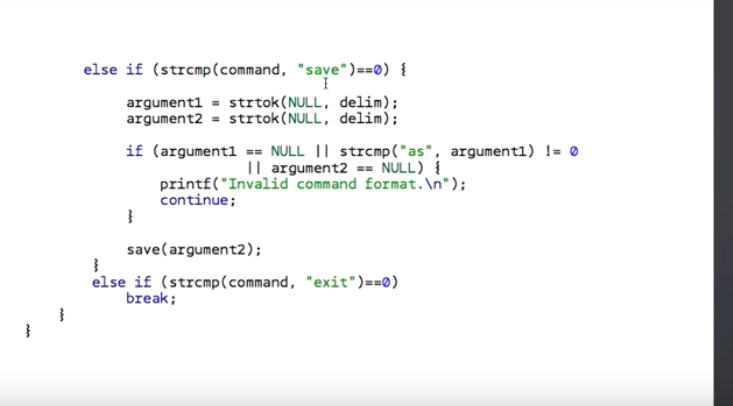
find 의 경우에도, find 다음에 사람이름이 나와야 한다.
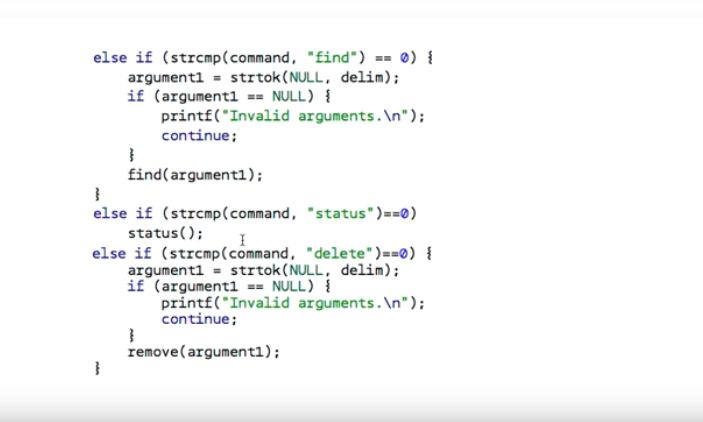


save의 포멧은 save as 파일이름
이로 인해 2가지 token이 필요하다.
if( argument1 == NULL || strcmp( "as" , argument1 ) ≠ 0 || argument2 == NULL )
as. 를 입력하지 않았거나
as 라고 정확하게 입력하지 않았거나
파일이름을 입력하지 않았거나
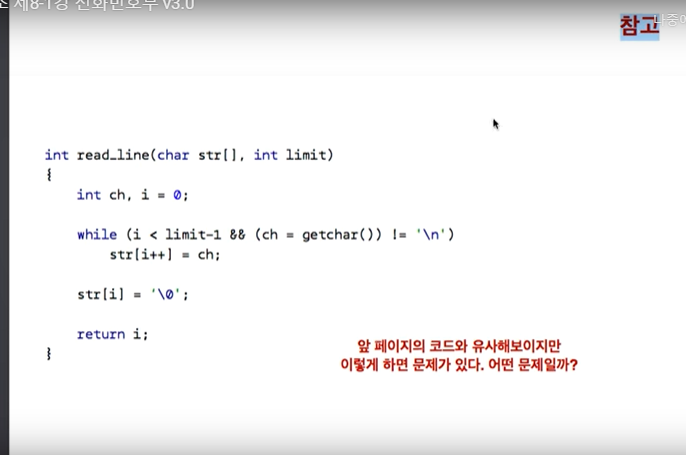
5. read_line( strtok )

보통 많은 프로그래머들은 fgets/ getline 등의 함수보다, 각자 사용자 정의 함수를 만들어 쓰는 경우가 많다.
readline은, 사용자가 한줄을 치고, \n 을 칠때까지의 내용을 str[]에 저장하는 것이다.
만일 limit 보다 큰 크기를 사용자가 입력하면, 한도 뒤의 내용은 잘린다.

위 함수와 다른 점은,
위 함수는 '\n' 가 나올 때까지, 어떤 유형이 입력되던 간에 문장 단위로 모두 읽어버린다.
즉, 위의 함수를 실행하고 나면, 한 라인을 끝까지 읽는데,
아래 함수는, 그렇지 않는다.
왜 ? 끝에 '\n' 이 나오지 않더라고, i < limit -1 이 되버리면,
더이상 읽지 않는다.
그리고, 다시 아래 함수를 main 함수내에서 실행할 때,
그다음 줄을 읽는 것이 아니라, 이 라인의 남아있는 부분을 읽게 될 것이다.
반면, 위의 함수는, '\n' 이 나오게 되면, 그 라인을 다 읽어버리고,
설령 그 라인을 다 읽지 못하더라도 ( limit 때문에 )
그저 바로 다음 라인의 내용을 읽는 것으로 넘어간다.
우리가 한 라인을 다 읽으면, 그것을 분석해야 한다.
사용자로부터 명령어 받을 때
ex. save as dirctory.txt
전에는 한 단어씩 순차적으로 입력 받았는데
이제는 line 을 통째로 입력받는다.
그렇고 나면, 이 명령의 의미를 해석하려면
이 문장을 save, as, direcdtory.txt 라는 문자로 쪼개야 한다.
이렇게 잘라진, 쪼개진 단위를 token 이라고 하고,
쪼개는 기준 ( 공백 혹은 \n) 등, 즉, 구분자 역할을 하는 것을 delimiter 라고 한다.
strtok Version 1

현재 '#' 단위로 자르는 것이다.
strtok을 사용할 때, 정확하게 기억할 것은 , 구분자가 연속해서 2개가 나오면 ex. ## . >>> 이 경우 어떻게 하냐 !!
#사이에, 길이가 0 짜리인 문자가 있다 ! 이런식으로 인식하게 해서 만드는 등.의 조치를 취하면 된다.
혹은 ### 를 , 구분자가 연속해서 나오면, 그것을 하나의 구분자로 인식해버리는 조치도 있다.
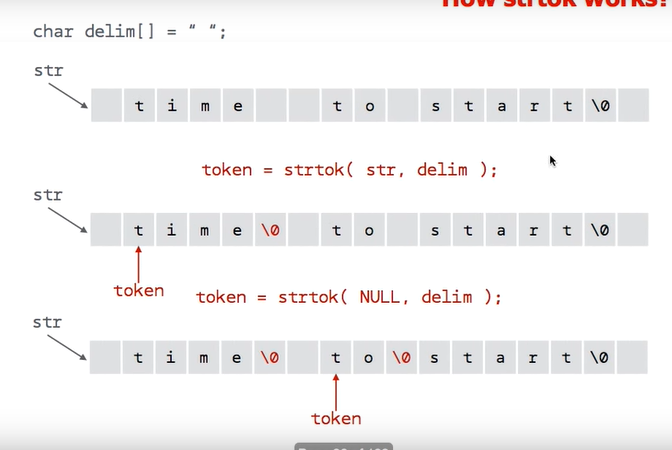
token = strtok( str, delim ) ;
즉, str > 문장을 포함하고 있는 배열의 주소.를 주기.
delim : 구분자가 포함하는 배열의 주소
즉, delim 자체도 하나의 string으로 주어지는 것이다.
즉, str 을 delim 기준으로 tokenizing 을 할 때, 첫번째 token, 첫번째 token의 시작 주소를 return 해주는 것이다. ex. now #
while 문은 token. 즉, 쪼개진 문자열들이 NULL 이 아닐 때까지 반복하는 것이다.
전체 str 문자열에 대한 tokenizing 이 끝나면, strtok은 NULL을 반환해줄 것.
그러므로, While 문은 token 이 NULL 이 아닐동안 반복
두번째 token 을 인식하기 위해서는 strtok을 연속해서 인식시켜주면 된다.
token = strtok( NULL, delim) ;
이때, 첫번째 strtok을 호출할 때는 token = strtok( str, delim) , 우리가 주는 문자열의 주소를 주어야 하지만,
그 다음부터는 첫번째 매개변수의 값이 NULL 이 된다.
token = strtok( NULL, delim) ;
이는 매우 특이한 특징이다.
사실, strtok은 C 표준 라이브러리가 제공해주는 함수중에서 가장 특이하다.
즉, 2번째 호출에서는 반드시 첫번째 매개변수로 str 이 아니라, NULL 이며, 두번째 token = strtok( NULL, delim) 에서는, 2번째 token의 주소, 즉, 2번째 token 의 첫번째 값의 주소
ex. ' is the time #'
에서 is 앞 '공백'의 주소를 return 해준다.
이런식으로 계속 반복이 이루어지는 것이다.
strtok Version2

이번에는 구문자가 " " 이다.
지금 str 을 보면, 여러개의 공백이 존재하는 것을 알 수 있다.
그리고 공백 여러개가 붙어있기도 하다.
str 은 " study hard, ~~~ " 에서,
study 앞에 있는 첫번째 공백 문자를 가리키고 있는 포인터라고 생각하면 된다.
그러면, 앞쪽에 있는 공백들. 은 모두 무시된다.
그리고 study 가 첫번째 token으로 인식된다.
or 앞에서도 마찬가지이다. 공백이 여러개. 즉, 공백이 한개가 아니라, 여러개가 연속적으로 붙어있는 것은 다 무시된다.
sleep뒤에 있는 공백 문자들도 모두 한꺼번에 무시된다.
strtok 작동원리

이제 첫번째 strtok 의 리턴값인, token은,
우리는 공백문자를 delimiter 로 사용하기 때문에, time 앞에 있는 공백 문자는 무시가 된다.
첫번째로 delimiter 가 아닌,
첫번째 문자를 찾아서, ( time 의 t )
token 이라는 포인터가 t 자리의 주소를 리턴해준다.
이제 strtok의 가장 특이한 점은
만일 그것이 다라면,
즉, token 이 t 를 가리키는 것이 다라면,
printf( "%s", token ) 을 하게 되면 어떻게 될까 ?
항상 printf 가 sting 을 출력할 때, NULL 을 그 string의 끝으로 인식한다.
만약 strtok이 단지, t , 의 주소를 리턴하는 것으로 그치게 되면
t 가 가리키는 문자열 을 print 하게 되면,
time to start \0 에서, time to start 전체가 출력될 것이다.
그런데 실제 그렇지 않았다
예를 들어,
여기 에서도, study hard or sleep 이렇게 전체 문자열이 출력된 것은 아니다.
study 만 따로 출력되었다.
결국, strtok 이 (위에서) time 뒤에 공백 문자를 넣어준다는 말이다.
즉, strtok은 단순히 첫번째 token 의 시작 주소를 찾아주는 것에 그치지 않고,
첫 token 이 끝나는 위치에 NULL 을 삽입해주므로, ( time\0)
첫번째 token을 출력해주면, time 이렇게 출력이 되는 것이다.
두번째 strtok을 쓸 때는 반드시 첫번째 매개변수가 NULL 이어야 한다고 했다.
이제 token은 두번째 token의 첫 문자를 찾아서 가고, 그 token 끝에 또 다시 NULL 을 넣어준다.

3번째 strtok을 하면, 그것이 리턴해주는 주소는 start 의 s 부분 주소이다.
strtok ( str[ ] , *str ) 의 차이

현재 보면, char str[ ] 이라는 배열 대신에, char *str 을 선언한 것을 알 수 있다.
그리고 실행 결과, 아무것도 안나오고 exit code가 0 이 아니라, 10인 것으로 보아, 오류가 있는 것을 알 수 있다.
왜 그런 걸까 ?
char * str = ~
은 엄밀히 말하면, string literal . 상수이다.
그리고, 변경이 불가능하다.
여기서 str 이 변경이 불가능하므로, strtok이 작동할 수 없는 것이다.
왜냐하면 strtok의 작동원리는 , 문자열 중간중간에 '\0'을 삽입하면서 진행되는데, char *str ~ , 은 , string literal 이고, 이는 수정이 불가능하므로, strtok 작동이 안돼서, 오류가 나오는 것이다.
char str[ ] ~
이 경우, char array 가 된다.
그래서 수정이 가능하게 되고
strtok 이 정상적으로 작동하게 된다.

자, after 를 출력하면 왜 now 만 출력되는 것일까??
왜냐하면 tokening 을 한 이후에는, now뒤에 현재 NULL, 이 들어간 상태이니까 !!