1) 추가할 기능
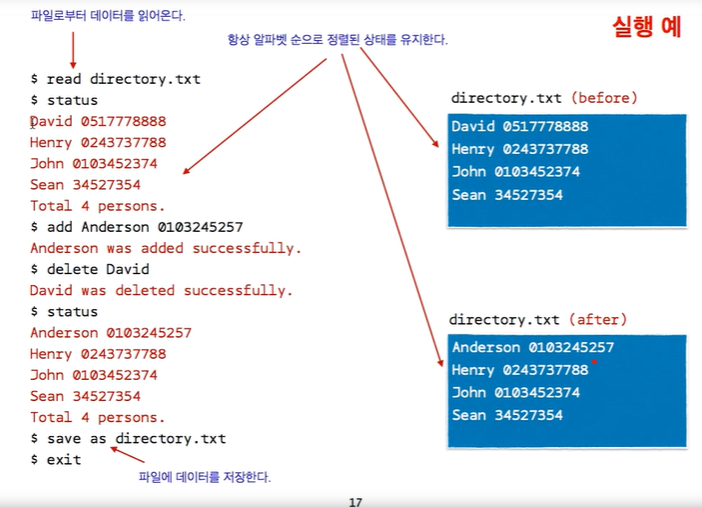
1) 이 프로그램에 추가할 기능은 전화번호부 정보를 file 에 저장하고, 다시 읽어오는 기능
먼저 file 안에 저장할 때 어떤 형식으로 저장할지 지정해야 하는데,
이 file 안에 한줄 당 한 사람의 정보가 저장이 된다.
이름. 전화번호.
이렇게 간단한 형식으로 저장이 된다.
프로그램 실행 후 read , 파일 이름. txt
이를 통해, 파일 안의 정보를 읽어오고,
add 를 통해, 사람의 정보를 추가
delete 을 통해 , 지우고
status 로 현황 파악
save로 현재 파일을 저장.
이러한 과정을 반복한다.
2) 뿐만 아니라, 저장을 할 때, 사람들의 이름이 알파벳 순서대로 저장될 수 있게 끔 해주어야 한다. ( 추가 기능 )
2) 전화번호부 2.0

2번째 전화번호부는, 1번째와 자료 자체가 동일하므로, '자료구조'는 1번째 전화번호부와 동일하다.
Main 함수

1) load

load 함수는 , fopen 하고, 내가 open 할 파일을 지정하고, load 함수는, 파일로부터 이 파일을 읽기 위해서 file 을 실행하는 것이므로 "r" 이라고 지정한다.
따라서 file 을 open 하는 모드가 "read" 모드이다.
if( fp == NULL ) : 어떤 이유에선지는 모르지만, file 을 open 하는데 실패했을 때의 예외처리
fscanf 의 경우, 파일의 끝에 도달하면 EOF ( End of File) 이라는 값을 리턴해준다.
fscanf 가 끝까지 도달하기 전까지 while 문을 돌고, 더이상 읽을 게 없으면 Eof 를 리턴해주므로, 그 때 while 문 종료된다.
while 문 내부로 돌아왔다는 것은, open에 성공했고,
fscanf( fp, "%s", buf1 ) 이라는 것은 ,
string 단위로 읽었다는 것이다.
첫번째 읽은 string은 당연히 어떤 사람의 이름일 것이다.
그러면 이어서, 그 사람의 전화번호를 읽어야 하므로
fscanf( fp, "%s", buf2 )
왜 이런 순서 ? 왜냐하면, 항상 파일은 이름—전화번호. 이런 순서로 되어 있기 때문이다.
즉 buf1 에는 그 사람의 이름, buf2 에는 그 사람의 전화번호부.가 저장되는 것이다.
그리고, 그렇게 읽은 사람의 정보를 names[n], number[n] 배열에 저장한다.
읽을 것을 다 읽으면 이제 그 파일을 닫아줘야 하므로
fclose( fp ) 를 통해 닫으면 된다.
2) save

which is "as", discarded ??
우리는 저장을 할 때 save as ~ 라고 저장하기로 했었자나 ( 위에서 )
여튼,
scanf 를 통해, 2개의 문자열을 연속해서 읽어야 한다.
첫번째 문자열은 그냥 'as'
이 'as ' 는 아무런 의미가 없으므로, 그냥 입력받고 무시.
fileName 은 우리가 저장할 fileName.
우리가 어떤 File 을 저장하기 위해서는, 그 File 을 열어야 하고,
fopen으로 파일을 여는데 , 이번에는 위와 달리 그 파일에 쓰기 위해서 여는 것이므로 "w" 모드로 파일을 열어야 한다.
만약 우리가 쓰려는 파일이 존재하지 않는다면 fopen 함수는, 그런 파일을 새로 만들어주는 기능을 한다.
무사히 열었다면, 이제 프로그램이 가지고 있는
사람의 이름과, 번호를 저장한다.
file 에 쓸 때는, fprintf 를 통해서 쓴다.
%s %s : 두 개의 문자열을, 중간에 한 칸 띄어서 쓰겠다.
역시 이 파일에 대한 볼일이 끝나면 fclose(fp)를 통해, 닫아준다.
3) 데이터 정렬 ( sort > 알파벳 순서)
데이터를 저장하는 방식에 있어서는 크게 2가지가 있다
1) bubblesort : 정렬 알고리즘 > 한번에 sorting
우리의 상황에서는 적절하지 않다.
왜냐하면 데이터가 고정된 것이 아니라, 계속 추가되기 때문이다.
즉, 이것을 적용하게 되면,
한명이 추가될 때마다 sorting algorit hm이 진행되어야 한다.
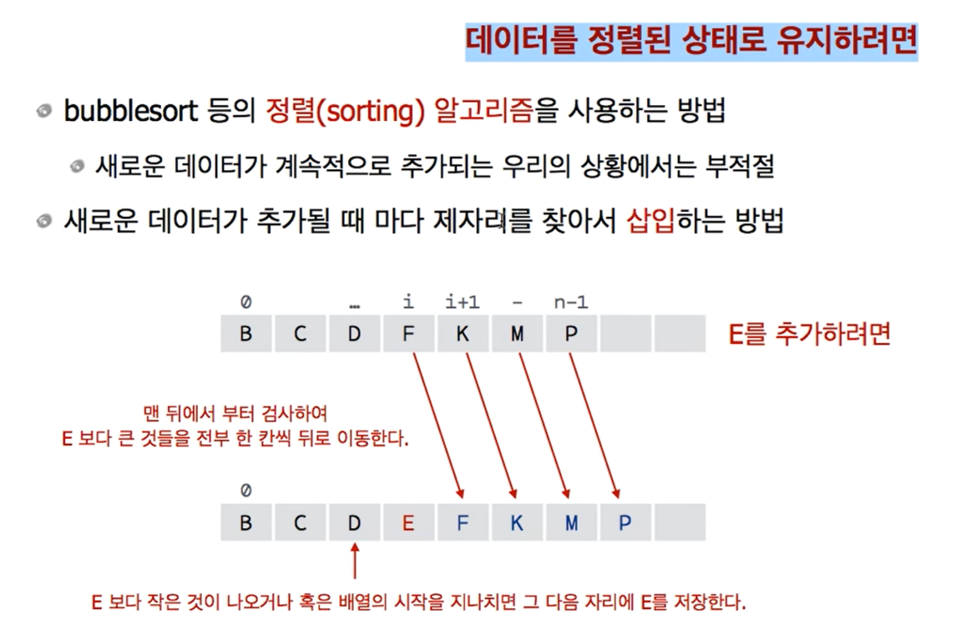
설명을 하자면, 만일 내가 E 를 중간에 넣고자 한다면 어떻게 해야할까 ?
먼저, B C D F K M P 에서, 맨 마지막에 있는 P부터 E 와 비교를 하면 된다.
P를 E 와 비교하면, P 가 E 보다 크다.
그렇다면 P보다 앞에, P 앞 쪽 어딘가에 E 가 들어가야 되고,
그 얘기는, 어쨋거나 P 는 한칸 뒤로 물러나야 될 상황
이와 같이, 내가 추가하려는 데이터를 맨 마지막 데이터부터 차례대로 비교하면서, E 보다 크면 한칸 뒤로 shift 시키는 것.
이러한 과정을 반복하는 것.
언제까지 ?
E 보다 작은 애가 나올 때까지.
D 는 E보다 작다.
그러면 한칸 씩 뒤로 이동시키면서 D 까지 왔으므로,
사실상 B C D F K M P 에서
F 자리는 사실상 이후 shift 가 되면, 비어있는 것이다.
F 는 한칸 뒤로 이사했으니까.
따라서, 처음으로 E 보다 작은 애가 나오면, 바로 뒤에 E 를 써주면 되는 것이다
물론, 여기에는 한가지 예외가 있다.
E 가 아니라, A 였다 ?
그렇게 되면, 그 어떤 애도 A 보다 작지 않아.
그러면 쭉 ~ 왼쪽으로 가게 되고,
B ~ P 는 모두 shift, 즉, 한칸 뒤로 물러날 것이다 .
B 옆까지 가게 되겠지.
그렇게 되면, 원래 B 자리, 즉, B 가 한칸 shift 되기 전,
맨 처음 자리에 A 가 들어가는 것이다.
'C_Data Structure_Algorithm > C telephone v2.0' 카테고리의 다른 글
| C 전화번호부 v2.0_2) (0) | 2020.02.29 |
|---|
