제

$ 를 쓰고, 한칸 띄고, 특정 문장을 입력하고, 엔터키를 치면
hello:5 와 같이, 내가 입력한 문자열과, 그 문자열의 길이가 나온다.
꼭 hello 와 같이, 하나의 문자만 쓰는 것이 아니어도 된다.
welcome to the class 와 같이, 공백이 포함될 수 있고,
이에 대한 문자열 길이는, 공백도 포함시켜서 count 된다.
VERSION 1 ( scanf )

// Version 1
# include<stdio.h>
# include<string.h>
int main() {
char buffer[ 40 ] ;
while( 1 ) {
printf("$ ");
scanf("%s" , buffer );
printf("%s : %d\n" , buffer, strlen(buffer) ) ;
return 0;
}
# include<stdio.h>
# include<string.h>
int main() {
char buffer1[ 40 ] ;
char buffer2[ 40 ] ;
char buffer3[ 40 ] ;
while( 1 ) {
printf("$ ");
scanf("%s" , buffer1 );
scanf("%s" , buffer2 );
scanf("%s" , buffer3 );
printf("%s : %d\n" , buffer1, strlen(buffer1) ) ;
printf("%s : %d\n" , buffer2, strlen(buffer2) ) ;
printf("%s : %d\n" , buffer3, strlen(buffer3) ) ;
}
return 0;
}주의할 오류
jhsdfg jshfg 와 같이, 중간에 공백을 둔 채로, 문자열을 입력한다고 해보자.
기본적으로 %s 는, 공백문자를 기준으로 잘라서, 단어 하나씩 입력받는 함수이므로,
공백 앞에 있는 것은 잘라버리고, 뒤에 것이 인식되는 것이다.
VERSION 2 ( gets )

// Version 2
int main() {
char buffer[ 40 ] ;
while( 1 ) {
printf("$ ");
gets( buffer ) ;
printf("%s : %d\n" , buffer, strlen(buffer) ) ;
return 0;
}
이와 같이, gets 함수를 쓰면, 이것은 '공백' 혹은 '단어' 기준이 아니라, 라인 단위로 입력받는 함수이다.
그렇기 때문에, 위와 달리, 입력한 모든 줄이 모두 출력되는 것이다.
VERSION 3 ( fgets )
/ Version 3
int main() {
char buffer[ 40 ] ;
while( 1 ) {
printf("$ ");
fgets( buffer, 40, stdin );
// fgets( s1, s2, s3) : 3개 매개변수
// s1 : fgets 가 저장할 buffer
// s2 : buffer ( 데이터를 읽어서 저장할 배열) 의 크기 , 우리가 위에서 40으로 설정했으니까, 40
// s3 : fgets 가 데이터가 읽어올 파일의 파일 포인터
// s3 : 여기서는 우리가 표준 입력데이터, 즉, 우리가 입력하는것을 받으므로
// stdin 을 쓰는 것이다.
printf("%s : %d\n" , buffer, strlen(buffer) ) ;
return 0;
}
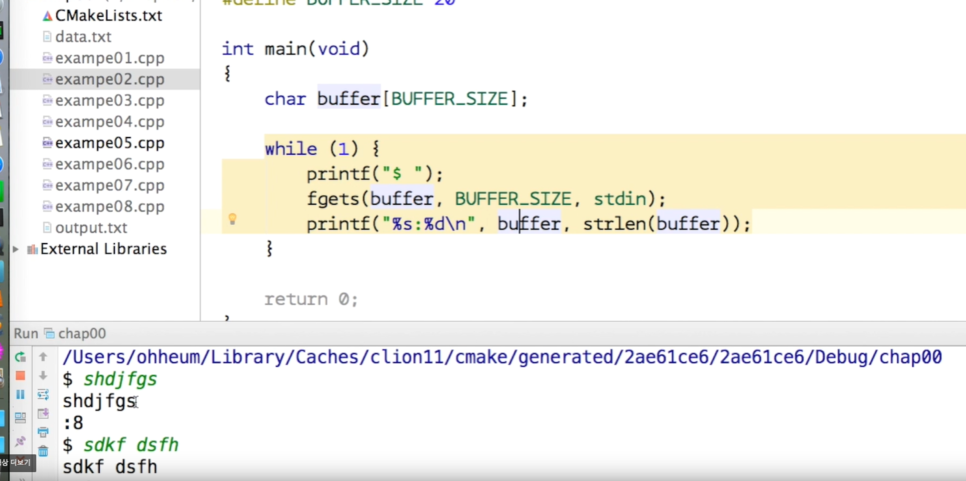
자세히 보면
shdjfgs
:8
이렇게 띄어쓰기가 되어서 출력된 것을 알 수 있다.
$ shdjfgs ( enter)
이 부분은 우리가 입력하는 부분이다.
마지막에, 엔터키를 만약 우리가 치게 되면,
fgets 는 문장을 쭉 읽다가 엔터, 즉, 줄바꿈 문자까지 이 buffer 에 저장한다. 그래서 아래에서 printf( "%s")에서, 줄바꿈 문자까지 포함된 buffer 를 출력하게 되므로, 위와 같이, 줄바꿈이 된 형태로 출력되는 것이다.
즉, fgets 와 gets 의 차이점
gets : \n 은 포함하지 않는다.
fgets : \n 을 포함한다.
이에 대한 해결책
int main() {
char buffer[ 40 ] ;
while( 1 ) {
printf("$ ");
fgets( buffer, 40, stdin );
buffer[ strlen(buffer) -1 ] = '\0'
printf("%s : %d\n" , buffer, strlen(buffer) ) ;
return 0;
}
buffer[ strlen(buffer) -1 ] = '\0' ??
buffer 의 마지막 부분을 , 즉, 우리가 위에서와 같이 엔터키를 치게 되면 buffer 의 마지막 부분은 '\n' 이 된다. 그 부분을 NULL로 바꿔주는 것이다.
즉, buffer[ strlen( buffer ) - 1] = '\n' 인 것이다. 원래는, !!
그런데 마지막 부분을 가리킬 것이면 strlen( buffer ) 만 써도 되는 것엔데, 왜 - 1 까지 해주는 거야 ?
왜냐하면 buffer[ 0 ] 이렇게 0 부터 시작하니까, - 1을 통해서 맞춰주는 것이지.
이를 실행하면 아래와 같이, 우리가 원하는 대로 실행된다.

그런데 fgets 의 문제가 있다.
바로 우리가 지정해준 BUFFER_SIZE 만큼만 입력한다는 것이다
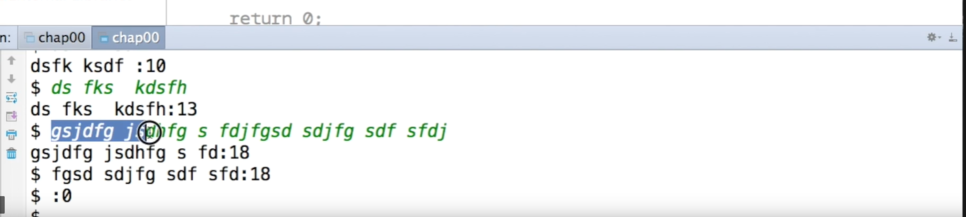
이와 같이, 우리가 지정한 20의 크기를 넘으면,
지정한 20 까지의 크기까지만 입력을 받고,
그 이후의 문자열들은 읽지 않는 다는 것을 알 수 있다.
VERSION 4 ( 사용자 정의 함수 )
// 기본적으로는 fgets 와 동일한 함수
// 즉, 내가 입력한 문장을 출력하는 것.
int read_line ( char str[] , int limit) {
// str[ ] : 입력받은 문자들을 저장할 문자배열.
// fgets 는, buffer_size 와 같이, 이미 지정된 크기를 넘으면 안되었다
// 즉, buffer 의 size 를 초과해서 입력받는 것을 방지하기 위해서
// str[ ] 의 size 를 limit 이라고 하는 것이다.
// 즉, 입력받은 문자들을 str[ ] 라는 곳에 저장을 해주고
// 입력받는 문자의 개수가 limit 을 넘지 않게 하기.
// limit 을 넘으면 , 나머지 뒷부분을 무시해라.
int ch , i = 0 ;
while ( ( ch = getchar() )!= '\n') {
// getchar( ) : 문자 단위로 한 문자씩 입력받는 것.
// 문자열을 읽어서 그것을 ch 라고 하고, 그것이 '\n' 이 아닐때까지 반복
// 여기서 읽은 문자를 str 배열의 i 번째 칸에 저장하기.
if( i < limit )
str[ i++ ] = ch;
// 문자의 수가 limit 을 초과해서 i 가 limit 을 넘지 않을때까지만 저장하기
// 그리고 limit 을 초과하면, 현재 str 에 저장된 문자개수는 i 개.
// 배열 index 로는 str[0] ~ str[i-1] 사이로 읽은 문자들이 저장되어 있을 것이다.
str[i] = '\0';
// 그래서, 마지막 i 번째 자리에 NULL 을 넣고, 반환하기.
return i;
// 이 str 가 실제 읽은 i 의 개수를 반환하는 것이지.
// 어차피 마지막 str[i]은, i+1 번째 이지만, null 이니까
}
int main() {
char buffer[ 40 ] ;
while( 1 ) {
printf("$ ");
int len = readline( buffer, BUFFER_SIZE) ;
// readline 이 리턴해주는 것을 len 으로 받기.
buffer[ strlen(buffer) -1 ] = '\0'
printf("%s : %d\n" , buffer, strlen(buffer) ) ;
return 0;
}
'C_Data Structure_Algorithm > C String' 카테고리의 다른 글
| 5) (예제2)C isspace, read_line(줄단위 읽기 ) (0) | 2020.02.27 |
|---|---|
| 3) 파일로 입출력하기 (0) | 2020.02.26 |
| 2) 문자열 기본 함수 (0) | 2020.02.25 |
| 1) 문자열 개요 (0) | 2020.02.25 |



